Amazon Rekognition
https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.html

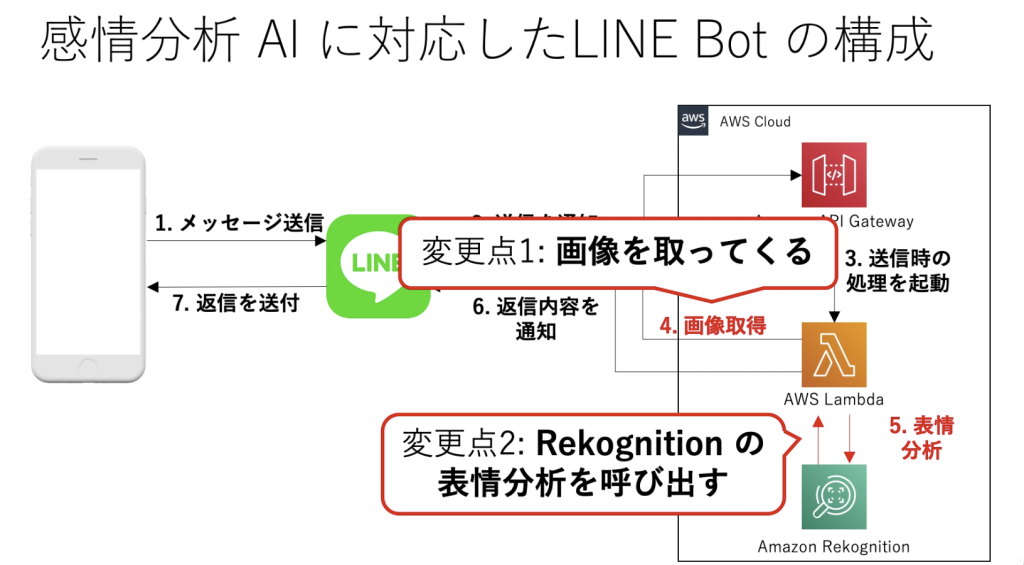
RekognitionはAmazonが提供する画像分析サービスであり、最近ではマスクをしている人としていない人なども検知することができるようです。今までとの大きな違いはLambdaとRekoginitionとの間で発生する表情分析です。テキストではなく、画像の受け取りが出来るようにコードを書く必要があります。今回はその中でもDetectFacesというサービスを使用していきます。



boto3というAWSのWebAPIをサポートしているサービスを利用する。
mylinebot.py
import os
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage, ImageMessage,
)
import boto3
handler = WebhookHandler(os.getenv('LINE_CHANNEL_SECRET'))
line_bot_api = LineBotApi(os.getenv('LINE_CHANNEL_ACCESS_TOKEN'))
client = boto3.client('rekognition')
def lambda_handler(event, context):
headers = event["headers"]
body = event["body"]
signature = headers['x-line-signature']
handler.handle(body, signature)
return {"statusCode": 200, "body": "OK"}
@handler.add(MessageEvent, message=TextMessage)
def handle_text_message(event):
""" TextMessage handler """
input_text = event.message.text
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=input_text))
@handler.add(MessageEvent, message=ImageMessage)
def handle_image_message(event):
message_content = line_bot_api.get_message_content(event.message.id)
file_path = "/tmp/sent-image.jpg"
with open(file_path, 'wb') as fd:
for chunk in message_content.iter_content():
fd.write(chunk)
with open(file_path, 'rb') as fd:
sent_image_binary = fd.read()
response = client.detect_faces(Image={'Bytes': sent_image_binary},
Attributes=["ALL"])
if all_happy(response):
message = "いい笑顔ですね!!"
else:
message = "ぼちぼちですね"
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text = message))
os.remove(file_path)
def all_happy(result):
"""検出した顔が全てhappyなら、tureを返す"""
for detail in result["FaceDetails"]:
if most_confident_emotion(detail["Emotions"]) != "HAPPY":
return False
return True
def most_confident_emotion(emotions):
max_conf = 0
result = ""
for e in emotions:
if max_conf < e["Confidence"]:
max_conf = e["Confidence"]
result = e["Type"]
return result
template.json
{
"AWSTemplateFormatVersion": "2010-09-09",
"Transform": "AWS::Serverless-2016-10-31",
"Parameters": {
"LineChannelAccessToken": {"Type": "String", "Description": "LINE のアクセストークン"},
"LineChannelSecret": {"Type": "String", "Description": "LINE のチャンネルシークレット"}
},
"Resources": {
"EndPointFunction": {
"Type": "AWS::Serverless::Function",
"Properties": {
"Runtime": "python3.8",
"CodeUri": "src",
"Handler": "mylinebot.lambda_handler",
"Environment": {"Variables": {
"LINE_CHANNEL_ACCESS_TOKEN": {"Ref": "LineChannelAccessToken"},
"LINE_CHANNEL_SECRET": {"Ref": "LineChannelSecret"}
}},
"Policies": [{"RekognitionDetectOnlyPolicy":{}}],
"Events": {
"API": {
"Type": "Api",
"Properties": {"Path": "/api_endpoint", "Method": "post"}
}
}
}
}
},
"Outputs": {
"ApiEndpointURL": {
"Description": "API Endpoint URL",
"Value": {"Fn::Sub": "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/${ServerlessRestApi.Stage}/api_endpoint"}
}
}
}
requirement.txt line-bot-sdk boto3
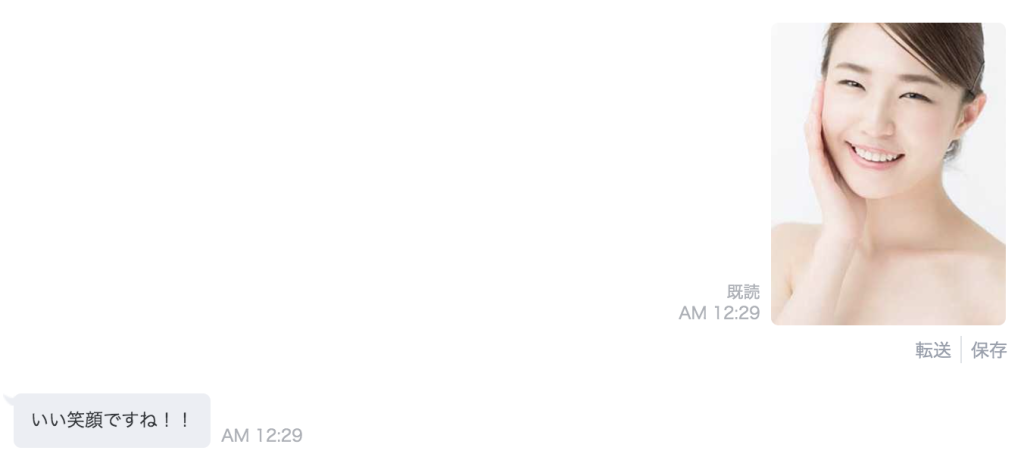
このように画像を受け取り、笑顔と判断してコメントを返すことが出来るようになりました。^^
https://shorturl.fm/zrGLA